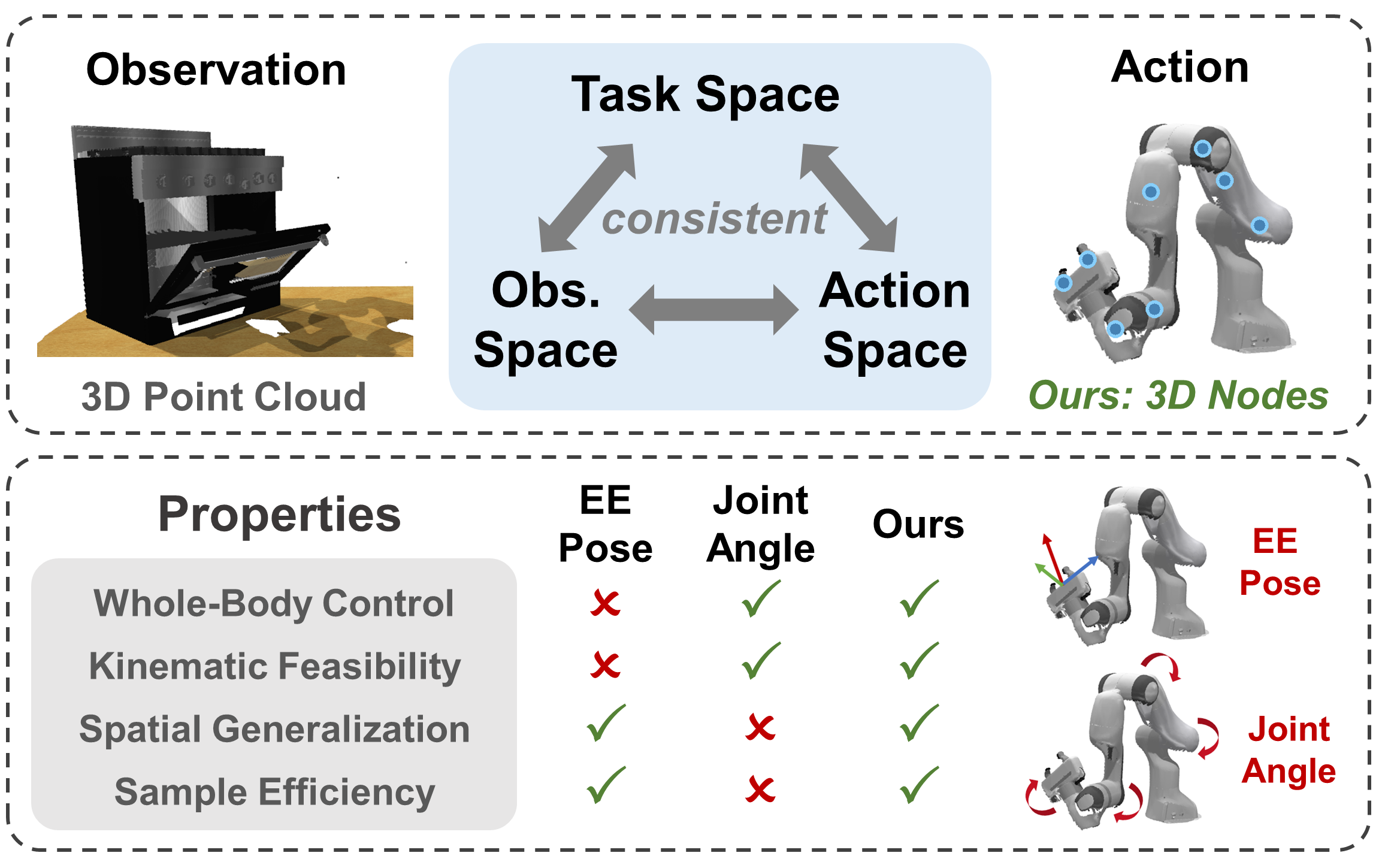
Whole-body control of robotic manipulators with awareness of full-arm kinematics is crucial for many manipulation scenarios involving body collision avoidance or body-object interactions, which makes it insufficient to consider only the end-effector poses in policy learning. The typical approach for whole-arm manipulation is to learn actions in the robot's joint space. However, the unalignment between the joint space and actual task space (i.e., 3D space) increases the complexity of policy learning, as generalization in task space requires the policy to intrinsically understand the non-linear arm kinematics, which is difficult to learn from limited demonstrations. To address this issue, this letter proposes a kinematics-aware imitation learning framework with consistent task, observation, and action spaces, all represented in the same 3D space. Specifically, we represent both robot states and actions using a set of 3D points on the arm body, naturally aligned with the 3D point cloud observations. This spatially consistent representation improves the policy's sample efficiency and spatial generalizability while enabling full-body control. Built upon the diffusion policy, we further incorporate kinematics priors into the diffusion processes to guarantee the kinematic feasibility of output actions. The joint angle commands are finally calculated through an optimization-based whole-body inverse kinematics solver for execution. Simulation and real-world experimental results demonstrate higher success rates and stronger spatial generalizability of our approach compared to existing methods in body-aware manipulation learning.
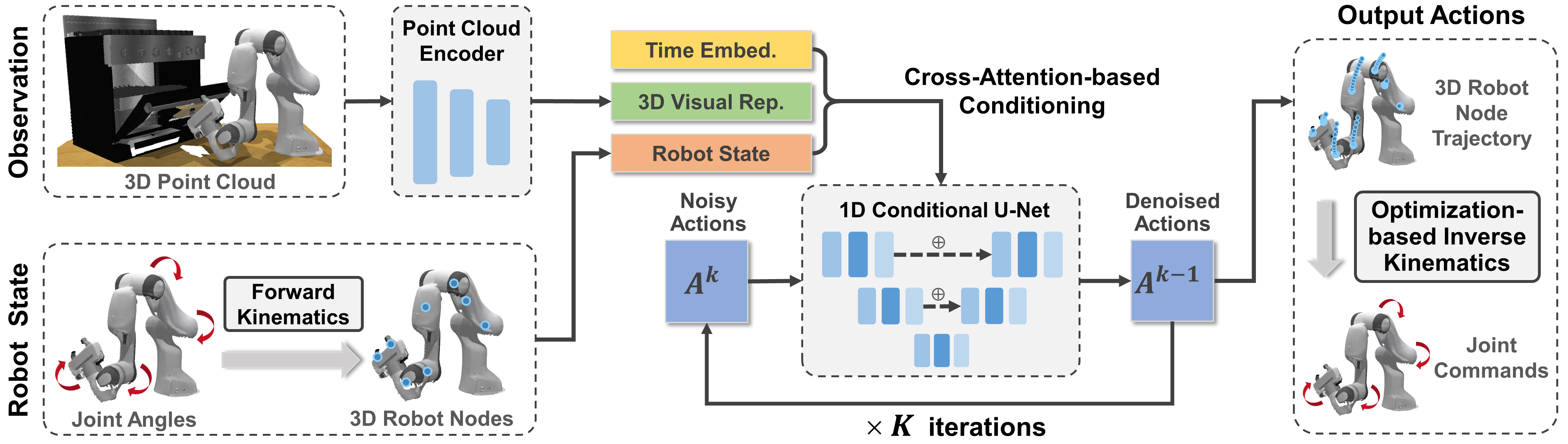
Overview of Kinematics-Aware Diffusion Policy (KADP). Taking the encoded 3D visual representations, the 3D robot nodes and time embeddings as input, diffusion model predicts the denoised 3D node trajectory iteratively. For execution, the joint angle commands are computed through an optimization-based whole-body inverse kinematics solver.
The robot only needs to grasp the object and lift it, which is designed to specifically analyze the spatial generalizability and sample efficiency of KADP. Since accurately controlling the end-effector pose is sufficient, DP3-EE is expected to perform well due to the alignment between observation and action space.
The robot should first grasp the handle and then follow a circular trajectory to open the door. Due to the narrow width of the handle, even small grasping positional error from the handle’s center will cause the gripper to lose contact with it in the subsequent motion. Controlling only the end-effector pose is also sufficient but this task is obviously more challenging compared to the pick up cube above.
The robot should first grasp a cube and then put it into a deep and narrow cabinet, which is designed to evaluate whole-body collision avoidance performance. The primary difficulties arise from two factors: 1) The robot must reach near the cabinet's deepest position, which requires the entire robot to remain nearly horizontal to avoid collision with the top surface; 2) The cabinet is only 4cm wider than the gripper, making the successful insertion highly sensitive to even slight positional inaccuracies.
The robot is required to press a button using its elbow instead of the gripper, making it meaningless to control only the end-effector pose. Learning directly from joint space is expected to yield good performance as only the angles of the first 3 joints change during the manipulation process.